Welcome to Subscribe On Youtube
Formatted question description: https://leetcode.ca/all/1236.html
1236. Web Crawler
Level
Medium
Description
Given a url startUrl and an interface HtmlParser, implement a web crawler to crawl all links that are under the same hostname as startUrl.
Return all urls obtained by your web crawler in any order.
Your crawler should:
- Start from the page:
startUrl - Call
HtmlParser.getUrls(url)to get all urls from a webpage of given url. - Do not crawl the same link twice.
- Explore only the links that are under the same hostname as
startUrl.
As shown in the example url above, the hostname is example.org. For simplicity sake, you may assume all urls use http protocol without any port specified. For example, the urls http://leetcode.com/problems and http://leetcode.com/contest are under the same hostname, while urls http://example.org/test and http://example.com/abc are not under the same hostname.
The HtmlParser interface is defined as such:
interface HtmlParser {
// Return a list of all urls from a webpage of given url.
public List<String> getUrls(String url);
}
Below are two examples explaining the functionality of the problem, for custom testing purposes you’ll have three variables urls, edges and startUrl. Notice that you will only have access to startUrl in your code, while urls and edges are not directly accessible to you in code.
Example 1:
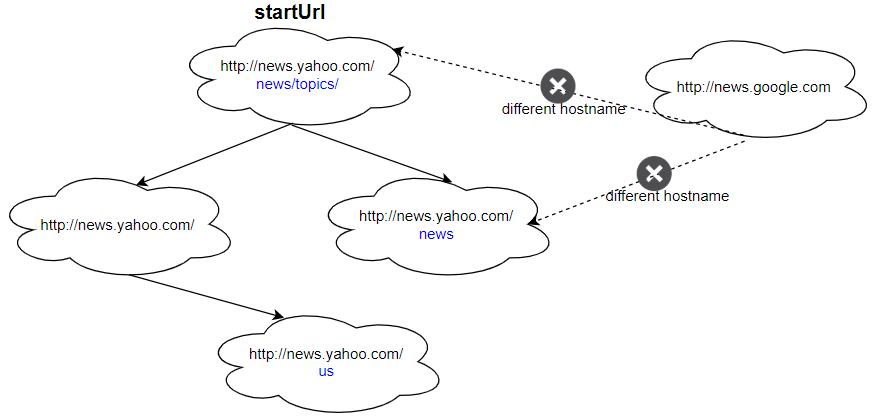
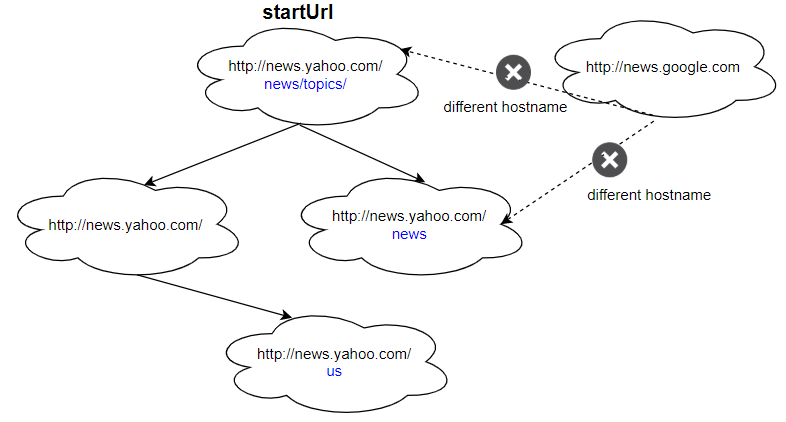
Input:
urls = [
"http://news.yahoo.com",
"http://news.yahoo.com/news",
"http://news.yahoo.com/news/topics/",
"http://news.google.com",
"http://news.yahoo.com/us"
]
edges = [[2,0],[2,1],[3,2],[3,1],[0,4]]
startUrl = "http://news.yahoo.com/news/topics/"
Output: [
"http://news.yahoo.com",
"http://news.yahoo.com/news",
"http://news.yahoo.com/news/topics/",
"http://news.yahoo.com/us"
]
Example 2:
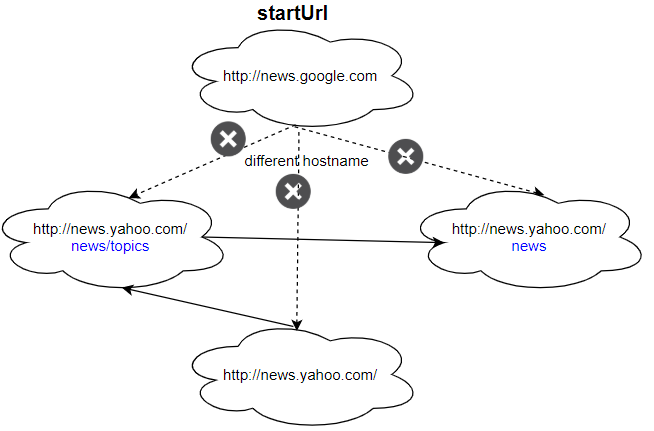
Input:
urls = [
"http://news.yahoo.com",
"http://news.yahoo.com/news",
"http://news.yahoo.com/news/topics/",
"http://news.google.com"
]
edges = [[0,2],[2,1],[3,2],[3,1],[3,0]]
startUrl = "http://news.google.com"
Output: ["http://news.google.com"]
Explanation: The startUrl links to all other pages that do not share the same hostname.
Constraints:
1 <= urls.length <= 10001 <= urls[i].length <= 300startUrlis one of theurls.- Hostname label must be from 1 to 63 characters long, including the dots, may contain only the ASCII letters from ‘a’ to ‘z’, digits from ‘0’ to ‘9’ and the hyphen-minus character (‘-‘).
- The hostname may not start or end with the hyphen-minus character (‘-‘).
- See: https://en.wikipedia.org/wiki/Hostname#Restrictions_on_valid_hostnames
- You may assume there’re no duplicates in url library.
Solution
First, obtain the host name of startUrl. Then do breadth first search starting from startUrl, and only visit the links that has the same hostname as startUrl. Each time a link with the same hostname as startUrl is visited, add the link to the result list. Continue searching until no more links are discovered.
Designing a web crawler
Designing a web crawler involves several key components and considerations. Here’s a high-level overview of the system design for a web crawler:
-
Define the Scope: Determine the purpose and scope of your web crawler. What websites or types of content do you want to crawl? What specific information do you want to extract?
-
Identify Seed URLs: Choose a set of initial seed URLs to start the crawling process. These URLs will serve as the entry points for your web crawler to begin its exploration.
-
Crawling Strategy: Decide on the crawling strategy you will employ. There are various approaches, including breadth-first, depth-first, or a combination of both. Consider factors like politeness (to avoid overloading servers) and prioritization of URLs.
-
URL Frontier: Implement a data structure, often referred to as a “URL frontier” or “crawl frontier,” to manage the URLs that need to be crawled. This structure typically follows a queue or priority queue, where newly discovered URLs are added and subsequently processed by the crawler.
-
HTTP Requesting: Develop the logic to send HTTP requests to the target websites. Use a library or framework that allows you to make HTTP requests efficiently. You may need to handle issues like cookies, sessions, authentication, and rate limiting.
-
Robots.txt Compliance: Respect the rules defined in the
robots.txtfiles found on websites. These files specify which parts of a website should not be crawled. Ensure that your web crawler adheres to these guidelines to maintain ethical crawling practices. -
Parsing and Extracting Data: Once a webpage is fetched, parse the HTML or other structured data formats (e.g., XML, JSON) to extract the desired information. You can use libraries like Beautiful Soup, Scrapy, or built-in features of your chosen programming language to assist in this process.
-
Data Storage: Decide how and where you will store the data collected by the web crawler. It can be a database, file storage, or any other suitable mechanism. Ensure that you have a well-defined data schema to organize and store the extracted data efficiently.
-
Duplicate URL Detection: Implement mechanisms to detect and handle duplicate URLs to avoid crawling the same page multiple times. This can involve maintaining a hash table or using other techniques to keep track of visited URLs.
-
Resilience and Error Handling: Account for network failures, timeouts, and other errors that may occur during the crawling process. Implement retry mechanisms, backoff strategies, and error logging to handle and recover from such situations gracefully.
-
Throttling and Politeness: Incorporate throttling mechanisms to ensure you don’t overload servers with excessive requests. Respect the website’s guidelines and implement polite crawling behavior to avoid being blocked or causing disruptions.
-
Distributed Crawling (optional): If scalability is a concern or you want to speed up the crawling process, you can design a distributed architecture where multiple crawler instances work in parallel. This typically involves distributing the URL frontier and coordinating the crawling process.
-
Monitoring and Analytics: Implement monitoring capabilities to track the progress of your web crawler. Collect metrics such as the number of crawled pages, processing time, error rates, etc. This information can help you assess the performance and identify areas for optimization.
-
Robustness and Security: Design the crawler with security in mind. Implement measures to handle malicious websites, handle unexpected content, and prevent vulnerabilities like injection attacks or cross-site scripting.
-
Legal and Ethical Considerations: Be aware of legal constraints and ethical guidelines for web crawling. Respect website terms of service, copyright laws, privacy policies, and any specific restrictions on content extraction.
These are the key aspects involved in designing a web crawler system. Depending on your specific requirements, you may need to delve deeper into each component and customize the implementation accordingly.
-
public class Web_Crawler { class Solution_dfs { Set<String> res = new HashSet<>(); // 返回结果 public List<String> crawl(String startUrl, HtmlParser htmlParser) { String host = getUrlHost(startUrl); // 取得域名 res.add(startUrl); // 将startUrl添加至返回结果 dfs(startUrl, host, htmlParser); // 开始dfs return new ArrayList<>(res); } void dfs(String startUrl, String host, HtmlParser htmlParser) { // 取得当前页面包含的所有链接 List<String> urls = htmlParser.getUrls(startUrl); // 通过每一个链接继续dfs for (String url : urls) { // 如果该链接已经爬过或是与网站域名不一致时跳过 if (res.contains(url) || !getUrlHost(url).equals(host)) { continue; } // 将该链接加入返回结果 res.add(url); // 继续dfs dfs(url, host, htmlParser); } } private String getUrlHost(String url) { String[] args = url.split("/"); return args[2]; } } class Solution_bfs { Set<String> res = new HashSet<>(); // 返回结果 public List<String> crawl(String startUrl, HtmlParser htmlParser) { String host = getUrlHost(startUrl); // 取得域名 Queue<String> q = new LinkedList<>(); // bfs用的queue res.add(startUrl); // 添加startUrl至返回结果 q.offer(startUrl); // 添加startUrl至bfs的Queue while (q.size() > 0) { String url = q.poll(); // 取得一个url // 查看当前url包含的所有链接 List<String> urls = htmlParser.getUrls(url); for (String u : urls) { // 循环每一个链接 // 如果该链接已经爬过或者不属于当前域名,跳过 if (res.contains(u) || !getUrlHost(u).equals(host)) { continue; } res.add(u); // 添加该链接至返回结果 q.offer(u); // 添加该链接至bfs的Queue } } return new ArrayList<>(res); } private String getUrlHost(String url) { String[] args = url.split("/"); return args[2]; } } interface HtmlParser { // Return a list of all urls from a webpage of given url. // This is a blocking call, that means it will do HTTP request and return when this request is finished. List<String> getUrls(String str); } } ############ /** * // This is the HtmlParser's API interface. * // You should not implement it, or speculate about its implementation * interface HtmlParser { * public List<String> getUrls(String url) {} * } */ class Solution { private Set<String> ans; public List<String> crawl(String startUrl, HtmlParser htmlParser) { ans = new HashSet<>(); dfs(startUrl, htmlParser); return new ArrayList<>(ans); } private void dfs(String url, HtmlParser htmlParser) { if (ans.contains(url)) { return; } ans.add(url); for (String next : htmlParser.getUrls(url)) { if (host(next).equals(host(url))) { dfs(next, htmlParser); } } } private String host(String url) { url = url.substring(7); return url.split("/")[0]; } } -
/** * // This is the HtmlParser's API interface. * // You should not implement it, or speculate about its implementation * class HtmlParser { * public: * vector<string> getUrls(string url); * }; */ class Solution { public: vector<string> ans; unordered_set<string> vis; vector<string> crawl(string startUrl, HtmlParser htmlParser) { dfs(startUrl, htmlParser); return ans; } void dfs(string& url, HtmlParser& htmlParser) { if (vis.count(url)) return; vis.insert(url); ans.push_back(url); for (string next : htmlParser.getUrls(url)) if (host(url) == host(next)) dfs(next, htmlParser); } string host(string url) { int i = 7; string res; for (; i < url.size(); ++i) { if (url[i] == '/') break; res += url[i]; } return res; } }; -
# """ # This is HtmlParser's API interface. # You should not implement it, or speculate about its implementation # """ # class HtmlParser(object): # def getUrls(self, url): # """ # :type url: str # :rtype List[str] # """ class Solution: def crawl(self, startUrl: str, htmlParser: 'HtmlParser') -> List[str]: def host(url): url = url[7:] return url.split('/')[0] def dfs(url): if url in ans: return ans.add(url) for next in htmlParser.getUrls(url): if host(url) == host(next): dfs(next) ans = set() dfs(startUrl) return list(ans) -
/** * // This is HtmlParser's API interface. * // You should not implement it, or speculate about its implementation * type HtmlParser struct { * func GetUrls(url string) []string {} * } */ func crawl(startUrl string, htmlParser HtmlParser) []string { var ans []string vis := make(map[string]bool) var dfs func(url string) host := func(url string) string { return strings.Split(url[7:], "/")[0] } dfs = func(url string) { if vis[url] { return } vis[url] = true ans = append(ans, url) for _, next := range htmlParser.GetUrls(url) { if host(next) == host(url) { dfs(next) } } } dfs(startUrl) return ans }