Welcome to Subscribe On Youtube
Question
Formatted question description: https://leetcode.ca/all/1242.html
Given a URL startUrl and an interface HtmlParser, implement a Multi-threaded web crawler to crawl all links that are under the same hostname as startUrl.
Return all URLs obtained by your web crawler in any order.
Your crawler should:
- Start from the page:
startUrl - Call
HtmlParser.getUrls(url)to get all URLs from a webpage of a given URL. - Do not crawl the same link twice.
- Explore only the links that are under the same hostname as
startUrl.

As shown in the example URL above, the hostname is example.org. For simplicity's sake, you may assume all URLs use HTTP protocol without any port specified. For example, the URLs http://leetcode.com/problems and http://leetcode.com/contest are under the same hostname, while URLs http://example.org/test and http://example.com/abc are not under the same hostname.
The HtmlParser interface is defined as such:
interface HtmlParser {
// Return a list of all urls from a webpage of given url.
// This is a blocking call, that means it will do HTTP request and return when this request is finished.
public List<String> getUrls(String url);
}
Note that getUrls(String url) simulates performing an HTTP request. You can treat it as a blocking function call that waits for an HTTP request to finish. It is guaranteed that getUrls(String url) will return the URLs within 15ms. Single-threaded solutions will exceed the time limit so, can your multi-threaded web crawler do better?
Below are two examples explaining the functionality of the problem. For custom testing purposes, you'll have three variables urls, edges and startUrl. Notice that you will only have access to startUrl in your code, while urls and edges are not directly accessible to you in code.
Example 1:
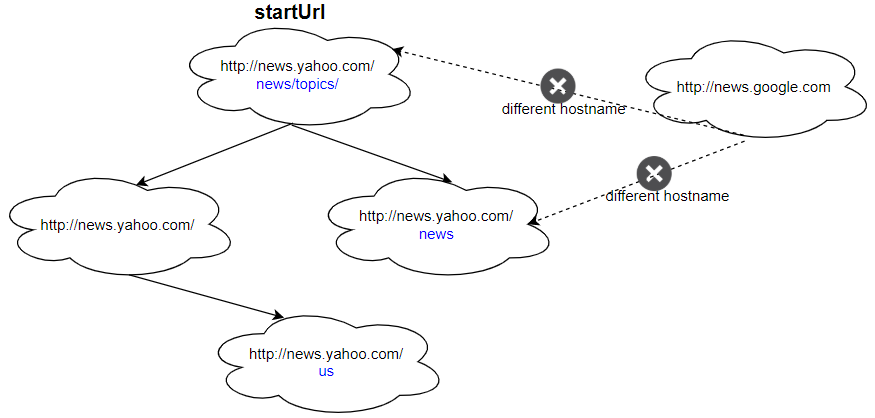
Input: urls = [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.google.com", "http://news.yahoo.com/us" ] edges = [[2,0],[2,1],[3,2],[3,1],[0,4]] startUrl = "http://news.yahoo.com/news/topics/" Output: [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.yahoo.com/us" ]
Example 2:
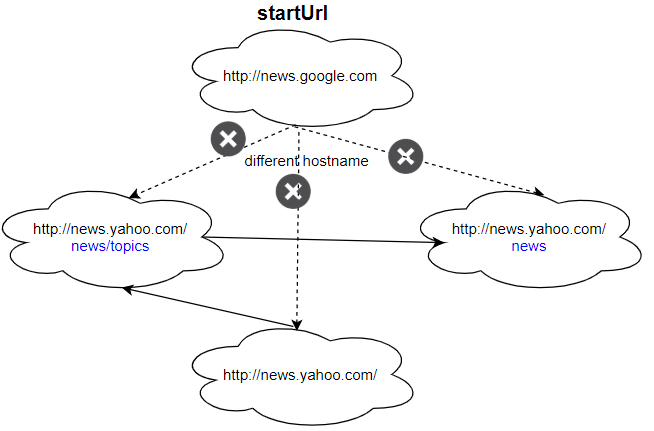
Input: urls = [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.google.com" ] edges = [[0,2],[2,1],[3,2],[3,1],[3,0]] startUrl = "http://news.google.com" Output: ["http://news.google.com"] Explanation: The startUrl links to all other pages that do not share the same hostname.
Constraints:
1 <= urls.length <= 10001 <= urls[i].length <= 300startUrlis one of theurls.- Hostname label must be from
1to63characters long, including the dots, may contain only the ASCII letters from'a'to'z', digits from'0'to'9'and the hyphen-minus character ('-'). - The hostname may not start or end with the hyphen-minus character ('-').
- See: https://en.wikipedia.org/wiki/Hostname#Restrictions_on_valid_hostnames
- You may assume there're no duplicates in the URL library.
Follow up:
- Assume we have 10,000 nodes and 1 billion URLs to crawl. We will deploy the same software onto each node. The software can know about all the nodes. We have to minimize communication between machines and make sure each node does equal amount of work. How would your web crawler design change?
- What if one node fails or does not work?
- How do you know when the crawler is done?
Algorithm
This topic is very novel. It means to write a simulated crawler program to crawl all web pages belonging to this domain name from a start page. LeetCode provides the crawler interface.
The topic requires the use of multi-threaded crawlers, otherwise it will time out.
- Use set to store crawled web pages. This set needs to support multi-threaded concurrent modification. I use
ConcurrentHashMap - As long as the list of stored results supports multi-thread concurrency, I use
Collections.synchronizedList
Follow up:
Assume we have 10,000 nodes and 1 billion URLs to crawl. We will deploy the same software onto each node. The software can know about all the nodes. We have to minimize communication between machines and make sure each node does equal amount of work.
1 . How would your web crawler design change?
After a node crawls a page, it will get a list of URLs to crawl next.
The brute force solution would be that this node communicates with all other nodes to see what are the links that haven’t been crawled.
A better solution would be that a node use Consistent Hashing to determine which node should handle that URL and send the URL to that node. In this way, each node becomes a task assigner, and the communication between nodes are minimized.
- When a new node is added to the system, a small fraction of links (crawled or not) that were or will be crawled in an old node will get migrated to the new node.
- When a node becomes offline, the links assigned to this node will be shared across other nodes.
And more:
- Add a database to store all the crawled data.
- Add serialize and de-serialize method, so that code can be distributed to 10k nodes with less bandwitch consumption.
- Add some centralized monitoring/scheduling strategy, to coordinate between hosts, if a crawler job failed in one stale host, restart it in another healthy host.
- Add some metric emitting, so that we can have a report of how many pages crawled, space usage to store them, etc.
- Kill long running thread, potentially something is going wrong.
Things to consider:
- Politeness/crawl rate
- DNS query
- Distributed crawling
- Priority crawling
- How to generate content signature?
- Duplicate detection
- what to do with similar content?
2 . What if one node fails or does not work?
Same as above, need a health ping or node management component, to move tasks on a stale host to a healthy host.
3 . How do you know when the crawler is done?
All tasks to all nodes are done, so still, job management componenet is needed.
Design question: Designing a distributed web crawler
Summary
Design a web crawler that fetches every page on en.wikipedia.org exactly 1 time. You have 10,000 servers you can use and you are not allowed to fetch a URL more than once. If a URL fails to be fetched (because of a timeout or server failure), it can be discarded.
Topics Discussed
- Hashing
- Distributed Systems
- Consistent Hashing
- Bloom Filter
- Trie Data Structures
- Consumer Groups (Kafka)
- Paxos
Requirements
Functional
- Download all (6.5m) URLs from en.wikipedia.com
- Only download each URL once
- Using 10k 2-core servers
- Only processing on the content is extract URLs otherwise persist the content to local storage
- Don’t crawl images
- Only crawl English Wikipedia
- Minimize network traffic between each server.
Non-functional
- No need to self-rate limit
- Fetch the content as fast as possible
High-level Analysis
How much storage will we need to store 6,500,000 URLs and their HTML documents?
- The average internet URL length is 66 characters. Since we don’t need to track the domain name or HTTPS prefix, we will round down to 60 characters.
60 characters = 60 bytes 60 bytes * 6,500,000 URLs = 390,000,000 bytes or 390 Megabytes
The average HTML page is about 100kb.
100 kilobytes * 6,500,000 documents = 650 Gigabytes
How do we want to store the URLs?
- Similar to the URL shortening system design problems, the most practical way of storing URLs that we have visited is a Set Structure for
O(1)lookup. While the hashes approach will consume more memory, since we will be storing the full URL, than aTrieData Structure or binary search tree, the lookups will be much faster (O(1)vsO(n)) and the additional memory cost will be manageable.
Where can we store the URLs?
- 390 Megabytes for all URLs can easily be stored in RAM, meaning we can get away with using an in-memory RAM solution for managing which URLs we have tracked.
- 65 Gigabytes is more than we can cost-effectively store in RAM on a single server. If we need to store the documents on a single server, we will need to write to the local hard drive. Because we have 10,000 servers, we could evenly distribute the documents, so each server would only need to store 3.9 GB of HTML. 3.9 GB can easily be stored in RAM at a reasonable price.
Where will be the limitations? CPU? Disk? Network?
- CPU: The most expensive task for the CPU will be extracting the URLs to be crawled from the HTML documents crawled so far. This task should take less than 1ms per document.
- Disk: As mentioned above, we probably don’t need to be writing to disk at all since the documents, when distributed across the 10k servers, will fit into memory.
- Network: Round trip to wikipedia.org for a single document may take ~200ms depending on their load and the distance our servers will be from theirs. This will be a Network bound task with the opportunity while waiting for the network responses for our CPUs to parse the existing HTML documents of their URLs.
Design Options
Option 1: Single server
- Naive approach: fetch a URL, extract URLs from the document, and query the next URL.
- Pros: Simple
- Cons: Does not utilize the 10k servers, wastes CPU cycles waiting for web requests to complete, server failure results in complete data loss.
Option 2: Distributed Systems
- Assign each URL to a specific server based on hashing.
- Master/slave design: map server IDs to IP addresses using DNS or pre-configuration.
- Each server tracks URLs it has crawled.
- Pros: Utilizes all 10k servers, minimizes network activity, fetches each URL once, handles distributed system failures.
- Cons: Uneven distribution of URLs among groups, some groups may have larger or more time-consuming URLs.
Directly talk to the server
- Retrieve server IP based on server number.
Using a DNS server
- Map hostnames to IP addresses.
APIs
- Implement APIs to receive URLs found by other servers.
- Use JSON and REST for routing requests.
Example API Request
POST /fetch_URLs HTTP/1.1
Host: 2.crawler.company.com
Body:
{
URLs: ["/wiki/Consistent_hashing", "/wiki/Hash_table"]
}
- Response:
202
Distributed Web Crawler Design Flowchart
- See source for the flowchart image.

Follow-up question: Distributing URLs with server failures
- Use “consumer groups” concept similar to Kafka.
- Divide the 10,000 servers into groups responsible for managing assigned URLs.
- Use consistency algorithm (e.g., Paxos) within a group to decide which machine fetches a URL.
- Consistent hashing with log(M) hashing algorithms can evenly distribute load among groups in case of group failures.
Example of Consistent Hashing
- See source for the example image.

Pros:
- Fully utilizes all 10,000 machines
- Minimizes network activity
- Fetches each URL once
- Handles distributed system failures
Cons:
- Uneven distribution of URLs among groups
- Some groups may have larger or more time-consuming URLs
More design examples
Code
-
import java.net.URI; import java.util.ArrayList; import java.util.Collections; import java.util.List; import java.util.Set; import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.ConcurrentSkipListSet; import java.util.stream.Collectors; import java.util.stream.Stream; public class Web_Crawler_Multithreaded { class Solution_1_synchronizedList { private final Set<String> set = Collections.newSetFromMap(new ConcurrentHashMap<String, Boolean>()); private final List<String> result = Collections.synchronizedList(new ArrayList<String>()); private String HOSTNAME = null; public List<String> crawl(String startUrl, HtmlParser htmlParser) { initHostName(startUrl); set.add(startUrl); getUrlDfs(startUrl, htmlParser); return result; } private boolean judgeHostname(String url) { int idx = url.indexOf('/', 7); String hostName = (idx != -1) ? url.substring(0, idx) : url; return hostName.equals(HOSTNAME); } private void initHostName(String url) { int idx = url.indexOf('/', 7); HOSTNAME = (idx != -1) ? url.substring(0, idx) : url; } private void getUrlDfs(String startUrl, HtmlParser htmlParser) { result.add(startUrl); List<String> res = htmlParser.getUrls(startUrl); List<Thread> threads = new ArrayList<>(); for (String url : res) { if (judgeHostname(url) && !set.contains(url)) { set.add(url); threads.add(new Thread(() -> { getUrlDfs(url, htmlParser); })); } } for (Thread thread : threads) { thread.start(); } try { for (Thread thread : threads) { thread.join(); // Waits for this thread to die. } } catch (InterruptedException e) { e.printStackTrace(); } } } class Solution_2_ConcurrentSkipListSet { public List<String> crawl(String startUrl, HtmlParser htmlParser) { // ConcurrentSkipListSet: Constructs a new, empty set that orders its elements // according to their {@linkplain Comparable natural ordering} // https://stackoverflow.com/questions/1904439/when-is-a-concurrentskiplistset-useful // ConcurrentSkipListSet and ConcurrentSkipListMap are useful when you need a sorted container // that will be accessed by multiple threads. // These are essentially the equivalents of TreeMap and TreeSet for concurrent code. Set<String> visited = new ConcurrentSkipListSet<>(); String hostname = getHostname(startUrl); visited.add(startUrl); return crawlDfs(startUrl, htmlParser, hostname, visited).collect(Collectors.toList()); } private Stream<String> crawlDfs(String startUrl, HtmlParser htmlParser, String hostname, Set<String> visited) { try (Stream<String> stream = htmlParser.getUrls(startUrl) .parallelStream() .filter(url -> isSameHostname(url, hostname)) .filter(visited::add) .flatMap(url -> crawlDfs(url, htmlParser, hostname, visited))) { return Stream.concat(Stream.of(startUrl), stream); } } private String getHostname(String url) { int idx = url.indexOf('/', 7); return (idx != -1) ? url.substring(0, idx) : url; } private boolean isSameHostname(String url, String hostname) { return url.startsWith(hostname) && (url.length() == hostname.length() || url.charAt(hostname.length()) == '/'); } } interface HtmlParser { // Return a list of all urls from a webpage of given url. // This is a blocking call, that means it will do HTTP request and return when this request is finished. List<String> getUrls(String str); } class Solution_CrawlerClass { public List<String> crawl(String startUrl, HtmlParser htmlParser) { // 取得startUrl的域名 String host = URI.create(startUrl).getHost(); // 新建一个线程,爬取startUrl中的所有链接 Crawler crawler = new Crawler(startUrl, host, htmlParser); // 初始化线程的返回结果 crawler.res = new ArrayList<>(); // 开启线程(相当于从起点开始dfs) crawler.start(); // 等待线程执行结束 Crawler.joinThread(crawler); // 返回线程的执行结果 return crawler.res; } } // 爬虫线程(相当于原始的dfs方法) static class Crawler extends Thread { String startUrl; // 当前url String hostname; // 域名 HtmlParser htmlParser; // 爬虫接口 // 返回结果 public volatile List<String> res = new ArrayList<>(); // 初始化线程 public Crawler(String startUrl, String hostname, HtmlParser htmlParser) { this.startUrl = startUrl; this.hostname = hostname; this.htmlParser = htmlParser; } @Override public void run() { // 获得当前url的域名 String host = URI.create(startUrl).getHost(); // 如果当前域名不属于目标网站,或者当前域名已经爬过,略过 if (!host.equals(hostname) || res.contains(startUrl)) { return; } // 将当前url加入结果集 res.add(startUrl); // 记录当前url页面包含的链接 // 每个链接启动一个新的线程继续dfs List<Thread> threads = new ArrayList<>(); for (String s : htmlParser.getUrls(startUrl)) { Crawler crawler = new Crawler(s, hostname, htmlParser); crawler.start(); threads.add(crawler); } // 等待每个子线程执行结束后,再结束当前线程 for (Thread t : threads) { joinThread(t); } } public static void joinThread(Thread thread) { try { thread.join(); } catch (InterruptedException e) { } } } } -
/** * // This is the HtmlParser's API interface. * // You should not implement it, or speculate about its implementation * class HtmlParser { * public: * vector<string> getUrls(string url); * }; */ class Solution { public: vector<string> crawl(string startUrl, HtmlParser htmlParser) { queue<string> q{ {startUrl} }; unordered_set<string> seen{ {startUrl} }; const string& hostname = getHostname(startUrl); // Threading const int nThreads = std::thread::hardware_concurrency(); vector<thread> threads; std::mutex mtx; std::condition_variable cv; auto t = [&]() { while (true) { unique_lock<mutex> lock(mtx); cv.wait_for(lock, 30ms, [&]() { return q.size(); }); if (q.empty()) return; auto cur = q.front(); q.pop(); lock.unlock(); const vector<string> urls = htmlParser.getUrls(cur); lock.lock(); for (const string& url : urls) { if (seen.count(url)) continue; if (url.find(hostname) != string::npos) { q.push(url); seen.insert(url); } } lock.unlock(); cv.notify_all(); } }; for (int i = 0; i < nThreads; ++i) threads.emplace_back(t); for (std::thread& t : threads) t.join(); return {begin(seen), end(seen)}; } private: string getHostname(const string& url) { const int firstSlash = url.find_first_of('/'); const int thirdSlash = url.find_first_of('/', firstSlash + 2); return url.substr(firstSlash + 2, thirdSlash - firstSlash - 2); } }; -
from threading import Thread, Lock from urllib.parse import urlparse # To parse URLs and extract hostname for comparison from typing import List class Solution: def crawl(self, startUrl: str, htmlParser: 'HtmlParser') -> List[str]: hostname = urlparse(startUrl).hostname seen = set([startUrl]) # Keep track of seen URLs to avoid re-crawling the same URL lock = Lock() # Lock for thread-safe operations on the seen set def dfs(url): for next_url in htmlParser.getUrls(url): if urlparse(next_url).hostname == hostname and next_url not in seen: with lock: # Ensure thread-safe write to the seen set if next_url not in seen: seen.add(next_url) dfs(next_url) def worker(): while True: with lock: if not unseen: return url = unseen.pop() dfs(url) unseen = [startUrl] # Stack of URLs to be crawled threads = [] num_threads = 10 # Or any number you deem appropriate based on the problem constraints # Start threads for _ in range(num_threads): thread = Thread(target=worker) thread.start() threads.append(thread) # Wait for all threads to finish for thread in threads: thread.join() return list(seen) #################################### reference https://levelup.gitconnected.com/multi-threaded-python-web-crawler-for-https-pages-e103f0839b71 class Crawler(threading.Thread): def __init__(self,base_url, links_to_crawl,have_visited, error_links,url_lock): threading.Thread.__init__(self) print(f"Web Crawler worker {threading.current_thread()} has Started") self.base_url = base_url self.links_to_crawl = links_to_crawl self.have_visited = have_visited self.error_links = error_links self.url_lock = url_lock def run(self): # we create a ssl context so that our script can crawl # the https sties with ssl_handshake. #Create a SSLContext object with default settings. my_ssl = ssl.create_default_context() # by default when creating a default ssl context and making an handshake # we verify the hostname with the certificate but our objective is to crawl # the webpage so we will not be checking the validity of the cerfificate. my_ssl.check_hostname = False # in this case we are not verifying the certificate and any # certificate is accepted in this mode. my_ssl.verify_mode = ssl.CERT_NONE # we are defining an infinite while loop so that all the links in our # queue are processed. while True: # In this part of the code we create a global lock on our queue of # links so that no two threads can access the queue at same time self.url_lock.acquire() print(f"Queue Size: {self.links_to_crawl.qsize()}") link = self.links_to_crawl.get() self.url_lock.release() # if the link is None the queue is exhausted or the threads are yet # process the links. if link is None: break # if The link is already visited we break the execution. if link in self.have_visited: print(f"The link {link} is already visited") break try: # This method constructs a full "absolute" URL by combining the # base url with other url. this uses components of the base URL, # in particular the addressing scheme, the network # location and the path, to provide missing components # in the relative URL. # in short we repair our relative url if it is broken. link = urljoin(self.base_url,link) # we use the header parameter to "spoof" the "User-Agent" header # value which is used by the browser to identify itself. This is # because some servers will only allow the connection if it comes # from a verified browser. In this case we are using FireFox header. req = Request(link, headers= {'User-Agent': 'Mozilla/5.0'}) # we are opening the url using a ssl handshake. response = urlopen(req, context=my_ssl) print(f"The URL {response.geturl()} crawled with \ status {response.getcode()}") # this returns the html representation of the webpage soup = BeautifulSoup(response.read(),"html.parser") # in this case we are finding all the links in the page. for a_tag in soup.find_all('a'): # we are checking of the link is already visited and (network location part) is our # base url itself. if (a_tag.get("href") not in self.have_visited) and (urlparse(link).netloc == "www.python.org"): self.links_to_crawl.put(a_tag.get("href")) else: print(f"The link {a_tag.get('href')} is already visited or is not part \ of the website") print(f"Adding {link} to the crawled list") self.have_visited.add(link) except URLError as e: print(f"URL {link} threw this error {e.reason} while trying to parse") self.error_links.append(link) finally: self.links_to_crawl.task_done() if __name__ == '__main__': print("The Crawler is started") base_url = input("Please Enter Website to Crawl > ") number_of_threads = input("Please Enter number of Threads > ") links_to_crawl = queue.Queue() url_lock = threading.Lock() links_to_crawl.put(base_url) have_visited = set() crawler_threads = [] error_links = [] #base_url, links_to_crawl,have_visited, error_links,url_lock for i in range(int(number_of_threads)): crawler = Crawler(base_url = base_url, links_to_crawl= links_to_crawl, have_visited= have_visited, error_links= error_links, url_lock=url_lock) crawler.start() crawler_threads.append(crawler) for crawler in crawler_threads: crawler.join() print(f"Total Number of pages visited are {len(have_visited)}") print(f"Total Number of Errornous links: {len(error_links)}") ###################################import multiprocessing from bs4 import BeautifulSoup from queue import Queue, Empty from concurrent.futures import ThreadPoolExecutor from urllib.parse import urljoin, urlparse import requests # ThreadPoolExecutor class MultiThreadedCrawler: def __init__(self, seed_url): self.seed_url = seed_url self.root_url = '{}://{}'.format(urlparse(self.seed_url).scheme, urlparse(self.seed_url).netloc) self.pool = ThreadPoolExecutor(max_workers=5) self.scraped_pages = set([]) self.crawl_queue = Queue() self.crawl_queue.put(self.seed_url) def parse_links(self, html): soup = BeautifulSoup(html, 'html.parser') Anchor_Tags = soup.find_all('a', href=True) for link in Anchor_Tags: url = link['href'] if url.startswith('/') or url.startswith(self.root_url): url = urljoin(self.root_url, url) if url not in self.scraped_pages: self.crawl_queue.put(url) def scrape_info(self, html): soup = BeautifulSoup(html, "html5lib") web_page_paragraph_contents = soup('p') text = '' for para in web_page_paragraph_contents: if not ('https:' in str(para.text)): text = text + str(para.text).strip() print(f'\n <---Text Present in The WebPage is --->\n', text, '\n') return def post_scrape_callback(self, res): result = res.result() if result and result.status_code == 200: self.parse_links(result.text) self.scrape_info(result.text) def scrape_page(self, url): try: res = requests.get(url, timeout=(3, 30)) return res except requests.RequestException: return def run_web_crawler(self): while True: try: print("\n Name of the current executing process: ", multiprocessing.current_process().name, '\n') target_url = self.crawl_queue.get(timeout=60) if target_url not in self.scraped_pages: print("Scraping URL: {}".format(target_url)) self.current_scraping_url = "{}".format(target_url) self.scraped_pages.add(target_url) job = self.pool.submit(self.scrape_page, target_url) job.add_done_callback(self.post_scrape_callback) except Empty: return except Exception as e: print(e) continue def info(self): print('\n Seed URL is: ', self.seed_url, '\n') print('Scraped pages are: ', self.scraped_pages, '\n') if __name__ == '__main__': cc = MultiThreadedCrawler("https://www.leetcode.ca") cc.run_web_crawler() cc.info()