Welcome to Subscribe On Youtube
582. Kill Process
Description
You have n processes forming a rooted tree structure. You are given two integer arrays pid and ppid, where pid[i] is the ID of the ith process and ppid[i] is the ID of the ith process's parent process.
Each process has only one parent process but may have multiple children processes. Only one process has ppid[i] = 0, which means this process has no parent process (the root of the tree).
When a process is killed, all of its children processes will also be killed.
Given an integer kill representing the ID of a process you want to kill, return a list of the IDs of the processes that will be killed. You may return the answer in any order.
Example 1:
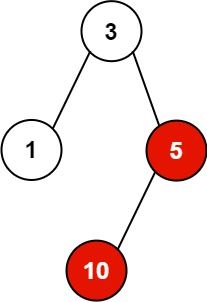
Input: pid = [1,3,10,5], ppid = [3,0,5,3], kill = 5 Output: [5,10] Explanation: The processes colored in red are the processes that should be killed.
Example 2:
Input: pid = [1], ppid = [0], kill = 1 Output: [1]
Constraints:
n == pid.lengthn == ppid.length1 <= n <= 5 * 1041 <= pid[i] <= 5 * 1040 <= ppid[i] <= 5 * 104- Only one process has no parent.
- All the values of
pidare unique. killis guaranteed to be inpid.
Solutions
Solution 1: DFS
We first construct a graph $g$ based on $pid$ and $ppid$, where $g[i]$ represents all child processes of process $i$. Then, starting from the process $kill$, we perform depth-first search to obtain all killed processes.
The time complexity is $O(n)$, and the space complexity is $O(n)$. Here, $n$ is the number of processes.
-
class Solution { private Map<Integer, List<Integer>> g = new HashMap<>(); private List<Integer> ans = new ArrayList<>(); public List<Integer> killProcess(List<Integer> pid, List<Integer> ppid, int kill) { int n = pid.size(); for (int i = 0; i < n; ++i) { g.computeIfAbsent(ppid.get(i), k -> new ArrayList<>()).add(pid.get(i)); } dfs(kill); return ans; } private void dfs(int i) { ans.add(i); for (int j : g.getOrDefault(i, Collections.emptyList())) { dfs(j); } } } -
class Solution { public: vector<int> killProcess(vector<int>& pid, vector<int>& ppid, int kill) { unordered_map<int, vector<int>> g; int n = pid.size(); for (int i = 0; i < n; ++i) { g[ppid[i]].push_back(pid[i]); } vector<int> ans; function<void(int)> dfs = [&](int i) { ans.push_back(i); for (int j : g[i]) { dfs(j); } }; dfs(kill); return ans; } }; -
class Solution: def killProcess(self, pid: List[int], ppid: List[int], kill: int) -> List[int]: def dfs(i: int): ans.append(i) for j in g[i]: dfs(j) g = defaultdict(list) for i, p in zip(pid, ppid): g[p].append(i) ans = [] dfs(kill) return ans -
func killProcess(pid []int, ppid []int, kill int) (ans []int) { g := map[int][]int{} for i, p := range ppid { g[p] = append(g[p], pid[i]) } var dfs func(int) dfs = func(i int) { ans = append(ans, i) for _, j := range g[i] { dfs(j) } } dfs(kill) return } -
function killProcess(pid: number[], ppid: number[], kill: number): number[] { const g: Map<number, number[]> = new Map(); for (let i = 0; i < pid.length; ++i) { if (!g.has(ppid[i])) { g.set(ppid[i], []); } g.get(ppid[i])?.push(pid[i]); } const ans: number[] = []; const dfs = (i: number) => { ans.push(i); for (const j of g.get(i) ?? []) { dfs(j); } }; dfs(kill); return ans; } -
use std::collections::HashMap; impl Solution { pub fn kill_process(pid: Vec<i32>, ppid: Vec<i32>, kill: i32) -> Vec<i32> { let mut g: HashMap<i32, Vec<i32>> = HashMap::new(); let mut ans: Vec<i32> = Vec::new(); let n = pid.len(); for i in 0..n { g.entry(ppid[i]).or_insert(Vec::new()).push(pid[i]); } Self::dfs(&mut ans, &g, kill); ans } fn dfs(ans: &mut Vec<i32>, g: &HashMap<i32, Vec<i32>>, i: i32) { ans.push(i); if let Some(children) = g.get(&i) { for &j in children { Self::dfs(ans, g, j); } } } }